AE, VAE, and VGAE
3 min readApr 17, 2020
AE


Loss function

VAE
Why do we need the variational autoencoders?[1]
One of the biggest advantages of the variational autoencoder is that VAE could generate new data from the original source dataset. In contrast, traditional autoencoder could only generate images that are similar to the original inputs.
Main idea[1]
The main idea of a variational autoencoder is that it embeds the input X to a distribution rather than a point. And then a random sample Z is taken from the distribution rather than generated from encoder directly.
The architecture of the Encoder and Decoder

Figure 6: An example of a variational autoencoder
Loss Function

Summary
The idea of VAE can be generalized by the image below:

VGAE (Variational Graph Autoencoders)
Adjacency Matrix[1]

Feature Matrix

The architecture of the Encoder and Decoder[1]
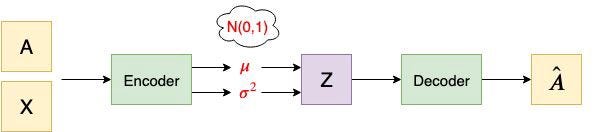
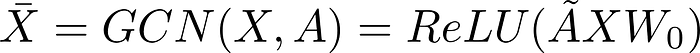
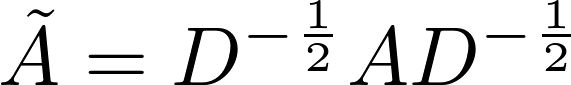

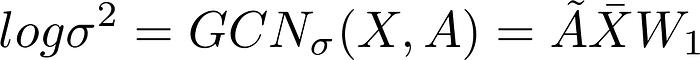
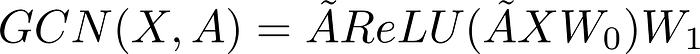
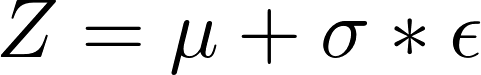
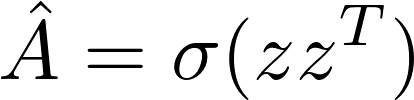


Loss Function
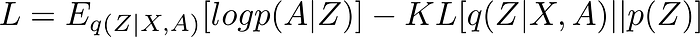
Reference
[1]Tutorial on Variational Graph Auto-Encoders
[2] Auto-Encoding Variational Bayes
[3] Variational Graph Auto-Encoders
[4] Graph Auto-Encoders TensorFlow implementation
